The diagram below illustrates how a decode-only large language model transforms a sequence of input tokens into a probability distribution over the next token — all in a single forward pass.
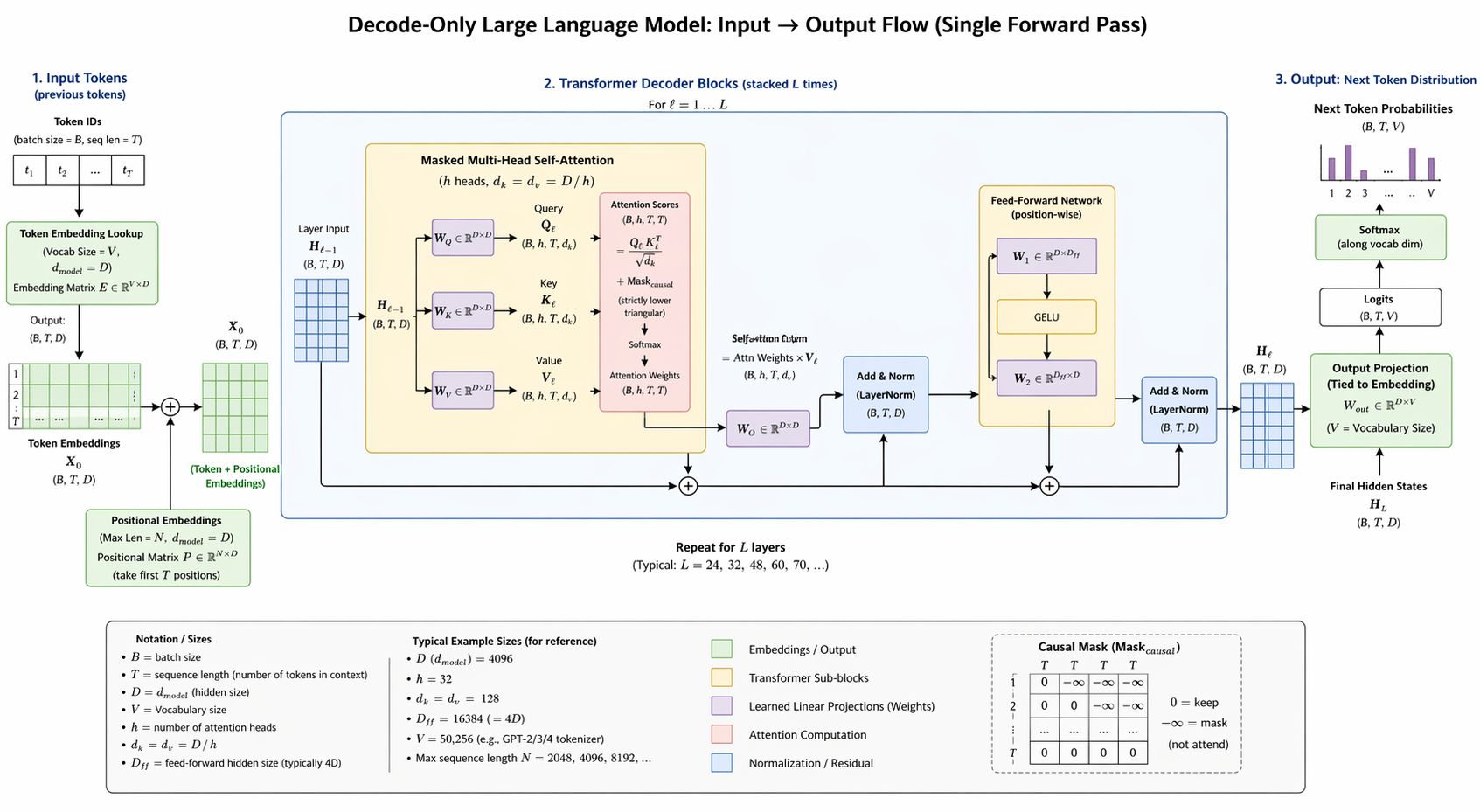
What the Diagram Shows
1. Input Tokens (left) The model begins with a sequence of discrete tokens. Each token is looked up in an embedding table to produce a dense vector of dimension d_model. Positional encodings are added so the model knows the order of tokens.
2. Transformer Blocks (center) The core of the model is a stack of N identical transformer blocks, each containing two sub-layers:
- Masked Multi-Head Self-Attention — each token attends to all preceding tokens (never future ones). The causal mask enforces this left-to-right constraint, which is what makes the architecture "decode-only." Attention outputs pass through learned linear projections (W_Q, W_K, W_V, W_O).
- Feed-Forward Network — a two-layer MLP with a GELU activation applied position-wise. This is where most of the model's parameters live.
Both sub-layers are wrapped with a residual connection and layer normalization (Add & Norm).
3. Output: Next Token Distribution (right) After the final transformer block, an output projection matrix maps the hidden state back to vocabulary size. A softmax converts these logits into a probability distribution. The model samples (or greedily selects) from this distribution to produce the next token. Repeat autoregressively to generate text.
Key Architectural Facts
| Component | Role |
|---|---|
| Token Embedding | Maps token IDs → dense vectors |
| Causal Mask | Prevents attending to future positions |
| Multi-Head Attention | Captures contextual relationships |
| Feed-Forward Network | Applies non-linear transformations per position |
| Layer Norm + Residual | Stabilizes training, preserves gradient flow |
| Output Projection + Softmax | Produces next-token probabilities |
The "decode-only" label distinguishes this design from encoder-decoder models (like the original Transformer). GPT-style models — including the GPT series, LLaMA, Mistral, and Claude — all follow this architecture. Its simplicity makes it highly scalable: stack more blocks, widen d_model, and train on more tokens.